This blog is written for the following two courses of KTU using python.
CST284-Mathematics for Machine Learning-KTU Minor course and
CST294-Computational Fundamentals for Machine Learning-KTU honors course.
Queries can be send to Dr Binu V P. 9847390760
Search This Blog
1.9 Linear Mapping and Matrix Representation for Linear Mapping
Linear Mapping ( Linear Transformation)
A linear Mapping (or simply transformation, sometimes called linear transformation) is a mapping between two vector spaces: it takes a vector as input and transforms it into a new output vector. A function is said to be linear if the properties of additivity and scalar multiplication are preserved, that is, the same result is obtained if these operations are done before or after the transformation. Linear functions are synonymously called linear transformations.A mapping $\Phi:V \to W$ preserves the structure of the vector space if
$\Phi(x+y)=\Phi(x)+\Phi(y)$
$\Phi(\lambda x)=\lambda \Phi(x)$
for all $x,y \in V$ and $\lambda \in \mathbb{R}$
Definition:
For vector spaces $V$ and $W$, a mapping $\Phi: V \to W$ is called a linear mapping( or vector space homomorphism/linear transformation) if
Definition:Consider a mapping $\Phi: V \mapsto W$, where $V$ and $W$ are arbitary sets. Then $\Phi$ is called
Injective (one to one) : if $\forall x,y \in V:\Phi(x)=\Phi(y) \implies x=y$
Surjective (onto): if $\Phi(V)=W$
Bijective(one to one and onto/injective and surjective)
If $\Phi$ is surjective, then every element in $W$ can be “reached” from $V$ using $\Phi$. A bijective $\Phi$ can be “undone”, i.e., there exists a mapping $\psi:W \to V$ so that $\Psi \Phi(x) = x$. This mapping is then called the inverse of $\Phi$ and normally denoted by $\Phi^{-1}$.
With these definitions, we introduce the following special cases of linear mappings between vector spaces $V $ and $W$:
Isomorphism: $\Phi : V \to W$ linear and bijective
Endomorphism: $V \to V$ linear
Automorphism: $\Phi: V \to V$ linear and bijective
We define $idv: V \to V, x \to x$ as the identity mapping or identity automorphism in $V$.
Theorem: Finite-dimensional vector spaces $V$ and $W$ are isomorphic if and only if $dim(V ) = dim(W).$
There exists a linear, bijective mapping between two vector spaces of the same dimension. Intuitively, this means that vector spaces of the same dimension are kind of the same thing, as they can be transformed into each other without incurring any loss.This also gives us the justification to treat $R^{m\times n}$ (the vector space of $m\times n$-matrices) and $R^{mn}$ (the vector space of vectors of length $mn$) the same, as their dimensions are $mn$, and there exists a linear, bijective mapping that transforms one into the other.
Remark: consider vector spaces $V, W,X$ Then
For linear mappings $\Phi: V \mapsto W$ and $\Psi: W \to X$, the mapping $\Psi \circ \Phi:V \to X$ is also linear.
If $\Phi: V \to W$ is an isomorphism, then $\Phi^{-1}: W \to V$ is an isomorphism too.
If $\Phi:V \to W, \Psi: V \to W$ are linear, then $\Phi + \Psi$ and $\lambda \Phi \in \mathbb{R}$ are linear too.
Example:
Let $F: \mathbb{R}^2 \to \mathbb{R}^2 $ given by $F(x,y)=(xy,x)$, show that $F$ is not linear
We know that for linearity
$F(\vec{v}+\vec{w})=F(\vec{v})+F(\vec{w})$
$F(c \vec{v})=c F(\vec{v})$
Let $\vec{v}=(2,3)$ and $\vec{w}=(3,4)$ and $\vec{v}+\vec{w}=(5,7)$
It is noted that $F(\vec{v}+\vec{w}) \ne F(\vec{v})+F(\vec{w})$ So $F(x,y)=(xy,x)$ is not linear.
Matrix Representation of Linear Mapping
Let $\Phi(x):R^n \to R^m $ be a matrix transformation: $\Phi(x)=Ax$ for an $m \times n$ matrix $A$. $\Phi(u+v)=A(u+v)=Au+Av=\Phi(u)+\Phi(v)$
$\Phi(cu)=A(cu)=cAu=c \Phi(u)$
for all vectors $u,v$ in $R^n$ and all scalars $c$. Since a matrix transformation satisfies the two defining properties, it is a linear transformation.A linear transformation necessarily takes the zero vector to the zero vector.Most linear functions can probably be seen as linear transformations in the proper setting. Transformations in the change of basis formulas are linear, and most geometric operations, including rotations, reflections, and contractions/dilations, are linear transformations. Even more powerfully, linear algebra techniques could apply to certain very non-linear functions through either approximation by linear functions or reinterpretation as linear functions in unusual vector spaces.
Linear transformations are most commonly written in terms of matrix multiplication. A transformation$T: V \to W$ from $m$-dimensional vector space $V$ to $n$-dimensional vector space $W$ is given by an $n \times m$ matrix $M$. Note, however, that this requires choosing a basis for $V$ and a basis for $W$, while the linear transformation exists independent of basis.
The linear transformation from $\mathbb{R}^3 $ to $\mathbb{R}^2$ defined by $T(x,\,y,\,z) = (x - y,\, y - z)$ is given by the matrix
A common transformation in Euclidean geometry is rotation in a plane, about the origin. By considering Euclidean points as vectors in the vector space $\mathbb{R}^2$, rotations can be viewed in a linear algebraic sense. A rotation of $v$ counterclockwise by angle $\theta$ is given by
import numpy as np import matplotlib.pyplot as plt T=np.array([[2,0],[0,3]]) v1=np.array([1,2]) v2=T.dot(v1) print("Red is the original vector-blue is the transformed vector") plt.plot([0,v1[0]],[0,v1[1]],'r') plt.plot([0,v2[0]],[0,v2[1]],'b') plt.show()
o/p
Red is the original vector-blue is the transformed vector
Coordinate Transformation
consider a vector space $V$ and an ordered basis $B=(b_1,\ldots,b_n)$ of $V$. For any $x \in V$ we can obtain unique representation of $x$ with respect to $B$.
$x=\alpha_1 b_1+ \cdots + \alpha_n b_n$.
Then $\alpha_1,\ldots,\alpha_n$ are called coordinates of $x$ with respect to $B$, and the vector $\alpha=\displaystyle \left[\begin{matrix}\alpha_1\\ \vdots\\ \alpha_n \end{matrix}\right] \in \mathbb{R}^n$ is the coordinate vector/coordinate representation of $x$ with respect to the ordered basis $B$.
A basis effectively defines a coordinate system. We are familiar with the Cartesian coordinate system in two dimensions, which is spanned by the canonical basis vectors $e_1,e_2$. In this coordinate system, a vector $x \in R^2$ has a representation that tells us how to linearly combine $e_1$ and $e_2$ to obtain $x$. However, any basis of $R^2$ defines a valid coordinate system,and the same vector $x$ from before may have a different coordinate representation in the new $(b_1,b_2)$ basis.
Coordinate Transformation Matrix
Consider vector spaces $V$ and $W$ with corresponding ordered bases $B=(b_1,\ldots,b_n)$ and $C=(c_1,\ldots,c_m)$.Moreover we consider liner mapping $\Phi: V \to W$.For $j \in \{1,\ldots,n\}$.
is the unique representation of $\Phi(b_j)$ with respect to $C$. Then we call the $m \times n$ matrix $A_\phi$, whose elements are given by
$A_\phi(i,j)=\alpha_{ij}$
the transformation matrix of $\Phi$ (with respect to the ordered bases B of V transformation and C of W).
The coordinates of $\Phi(b_j)$ with respect to the ordered basis $C$ of $W$ are the j-th column of $A_\phi$. Consider (finite-dimensional) vector spaces $V,W$ with ordered bases $B,C$ and a linear mapping $\Phi : V \to W $ with transformation matrix $A_\phi$.
If $\hat{x}$ is the coordinate vector of $x \in V$, with respect to $B$ and $\hat{y}$ the coordinate vector of $y=\Phi(x) \in W$ with respect to C; then
$\hat{y}=A_\phi\hat{x}$
This means that the transformation matrix can be used to map coordinates with respect to an ordered basis in $V$ to coordinates with respect to an ordered basis in $W$.
Example:
Consider a homomorphism $\Phi: V \to W$ and ordered bases $B=(b_1,\ldots,b_n)$ of $V$ and $C=(c_1,\ldots,c_n)$ of $W$ with
$\Phi(b_1)=c_1-c_2+3c_3-c_4$
$\Phi(b_2)=2c_1+c_2+7c_3+2c_4$
$\Phi(b_3)=3c_2+c_3+4c_4$
The transformation matrix $A_\phi$ with respect to $B$ and $C$ satisfies $\Phi(b_k)=\sum_{i=1}^{4} \alpha_{ik}c_i$, for $k=1,\ldots,3$ and is given as
You can use a change of basis matrix to go from a basis to another. To find the matrix corresponding to new basis vectors, you can express these new basis vectors (i’ and j’) as coordinates in the old basis (i and j).
Using Linear Combinations
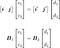
Let’s express the vector $v$ as a linear combination of the input and output basis vectors:
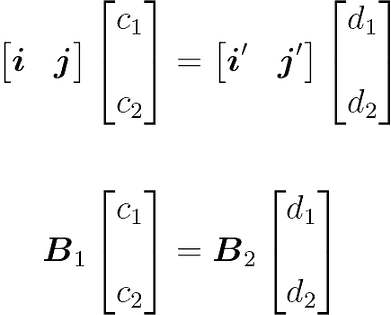
The scalars $c_1$ and $c_2$ are weighting the linear combination of the input basis vectors, and the scalars $d_1$ and $d_2$ are weighting the linear combination of the output basis vectors. You can merge the two equations:
Now, let’s write this equation in matrix form:
The vector containing the scalars $c_1$ and $c_2$ corresponds to $[v]B_1$ and the vector containing the scalars $d_1$ and $d_2$ corresponds to $[v]B_2$. We have:
That’s good, this an equation with the term you want to find: $[v]B_2$. You can isolate it by multiplying each side by $B_2^{-1}:$
You have also:
The term $B_2^{-1} B_1$ is the inverse of $B_1^{-1} B_2$, which is the change of basis matrix $C$. This shows that $C^{-1}$ allows you to convert vectors from an input basis $B_1$ to an output basis $B_2$ and $C$ from $B_2$ to $B_1$.
In the context of this example, since $B_1$ is the standard basis, it simplifies to:
This means that, applying the matrix $B_2 ^{-1}$ to $[v]B_1$ allows you to change its basis to $B_2$.
Lets implement the previous example in python
Note that you have to consider the base vectors as column vectors of the matrix
import numpy as np
B1=np.array([[1,0],[0,1]])
B2=np.array([[1,1],[-1,1]])
c1=np.array([2,3])
print("Base B1- standard")
print(B1)
print("New Base B2")
print(B2)
print("coordinates in base B1")
print(c1)
print("new coordinate in new base B2")
c2=(np.linalg.inv(B2)).dot(B1.dot(v1.T))
print(c2)
print("converting back to the original base")
c1=(np.linalg.inv(B1)).dot(B2.dot(c2.T))
print(c1)
O/P Base B1- standard
[[1 0]
[0 1]]
New Base B2
[[ 1 1]
[-1 1]]
coordinates in base B1
[2 3]
new coordinate in new base B2
[-0.5 2.5]
converting back to the original base
[2. 3.]
Show that the mapping $T:(a,b) \to (a+2,b+3)$ of $V_2(R)$ into itself is not a linear transformation. Here $R$ is the field of real numbers. ( university qn)
Introduction About Me Syllabus Course Outcomes and Model Question Paper University Question Papers and Evaluation Scheme -Mathematics for Machine learning CST 284 KTU Overview of Machine Learning What is Machine Learning (video) Learn the Seven Steps in Machine Learning (video) Linear Algebra in Machine Learning Module I- Linear Algebra 1.Geometry of Linear Equations (video-Gilbert Strang) 2.Elimination with Matrices (video-Gilbert Strang) 3.Solving System of equations using Gauss Elimination Method 4.Row Echelon form and Reduced Row Echelon Form -Python Code 5.Solving system of equations Python code 6. Practice problems Gauss Elimination ( contact) 7.Finding Inverse using Gauss Jordan Elimination (video) 8.Finding Inverse using Gauss Jordan Elimination-Python code Vectors in Machine Learning- Basics 9.Vector spaces and sub spaces 10.Linear Independence 11.Linear Independence, Basis and Dimension (video) 12.Generating set basis and span 13.Rank of a Matrix 14.Linear Mapping...
The Singular Value Decomposition ( SVD) of a matrix is a central matrix decomposition method in linear algebra.It can be applied to all matrices,not only to square matrices and it always exists.It has been referred to as the 'fundamental theorem of linear algebra'( strang 1993). SVD Theorem: Let $A^{m \times n}$ be a rectangular matrix of rank $r \in [0,min(m,n)]$. The SVD of A is a decomposition of the form. $A= U \Sigma V^T $ with an orthogonal matrix $U \in \mathbb{R}^{m \times m}$ with column vectors $u_i, i=1,\ldots,m$ and an orthogonal matrix $V \in \mathbb{R}^{n \times n}$ with column vectors $v_j, j=1,\ldots,n$.Moreover, $\Sigma$ is an $m \times n$ matrix with $\sum_{ii} = \sigma \ge 0$ and $\sigma_{ij}=0, i \ne j$. The diagonal entries $\Sigma_i=1,\ldots,r$ of $\sigma$ are called singular values . $u_i$ are called left singular vectors , and $v_j$ are called right singular vectors .By convention singular values are ordered ie; $\sigma_1 \ge \sigma_2 \ldots \sigma_r \...
Elementary Transformations Key to solving a system of linear equations are elementary transformations that keep the solution set the same, but that transform the equation system into a simpler form: Exchange of two equations (rows in the matrix representing the system of equations) Multiplication of an equation (row) with a constant Addition of two equations (rows) Add a scalar multiple of one row to the other. Row Echelon Form A matrix is in row-echelon form if All rows that contain only zeros are at the bottom of the matrix; correspondingly,all rows that contain at least one nonzero element are on top of rows that contain only zeros. Looking at nonzero rows only, the first nonzero number from the left pivot (also called the pivot or the leading coefficient) is always strictly to the right of the pivot of the row above it. The row-echelon form is where the leading (first non-zero) entry of each row has only zeroes below it. These leading entries are called...






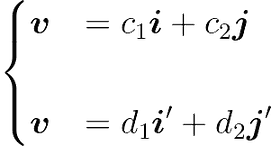


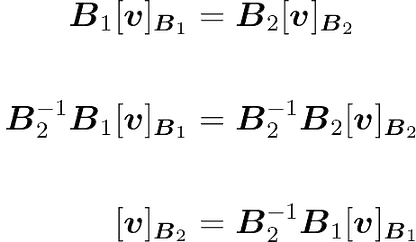
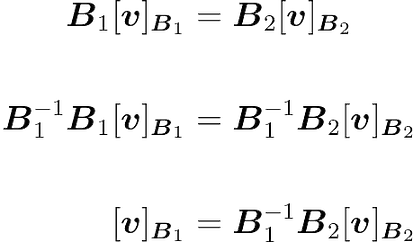
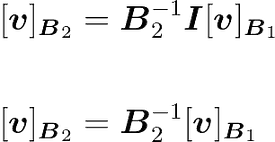


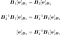

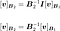
Comments
Post a Comment