This blog is written for the following two courses of KTU using python.
CST284-Mathematics for Machine Learning-KTU Minor course and
CST294-Computational Fundamentals for Machine Learning-KTU honors course.
Queries can be send to Dr Binu V P. 9847390760
Search This Blog
Row space, Column space and Null space
Row Space
The span of row vectors of any matrix, represented as a vector space is called row space of that matrix.
or
If we represent individual row as a vector, then the vector space formed by set of linear combination of all those vectors will be called row space of that matrix.
Then the row space is Span of these row vectors . $Span( v1,v2,v3)$ where $v1=(1,2,3), v2=(4,5,6),v3=(7,8,9)$
If there are linearly depended vectors, we have to avoid those vectors.Linearly independent vectors can be found by converting the vectors into row reduced echelon form.For example consider
The first and second columns are the pivot column.So the column space is the span of $[1,2,1]$ and $[2,4,1]$. the third column is a dependent column which is a linear combination of first two.
Both of these spaces have same dimension (same number of independent vectors) and that dimension is equal to rank of matrix.
Because, rank of matrix is maximum number of linearly independent vectors in rows or columns and dimension is maximum number of linearly independent vectors in a vector space (like column space or row space).
Rows and columns of a matrix have same rank so the have same dimension.
Null space
We are familiar with matrix representation of system of linear equations.
$Ax=0$
Here $A$ is coefficient matrix, $x$ is variable vector and 0 represents a vector of zeros.We can also find it’s solution (values of variables for which the equation above is satisfied) using Gaussian Elimination algorithm.
If we take a set of all possible solution vectors (all possible values of $x$), then the vector space formed out of that set will be called null space.
Or
Null space contains all possible solutions of a given system of linear equations.Taking an example
Solution vector of system of linear equations above is
So this system of linear equations has two vectors in null space.[0,0] and [2,1].
Null space contains all the linear combinations of solution.Null space always contains zero vector.
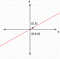
Red line represents the null space of system of linear equations Nullity
Dimension of null space is called nullity. Nullity of the system above is 1.
Index theorem(Rank Nullity Theorem): For an $m \times n$ matrix $A$,
$rank(A) + nullity(A) = n$
Null Space ( Python code)
from sympy import Matrix
M = Matrix([[1, 3, 0], [-2, -6, 0], [3, 9, 6]])
M.nullspace()
[Matrix([ [-3], [ 1], [ 0]])]
Finding nullity ( python code)
from sympy import Matrix
A = [[1, 2, 0], [2, 4, 0], [3, 6, 1]]
A = Matrix(A)
# Number of Columns
NoC = A.shape[1]
# Rank of A
rank = A.rank()
# Nullity of the Matrix
nullity = NoC - rank
print("Nullity : ", nullity)
Find a basis for the row space, column space and null space of the matrix given below ( university qn)
Introduction About Me Syllabus Course Outcomes and Model Question Paper University Question Papers and Evaluation Scheme -Mathematics for Machine learning CST 284 KTU Overview of Machine Learning What is Machine Learning (video) Learn the Seven Steps in Machine Learning (video) Linear Algebra in Machine Learning Module I- Linear Algebra 1.Geometry of Linear Equations (video-Gilbert Strang) 2.Elimination with Matrices (video-Gilbert Strang) 3.Solving System of equations using Gauss Elimination Method 4.Row Echelon form and Reduced Row Echelon Form -Python Code 5.Solving system of equations Python code 6. Practice problems Gauss Elimination ( contact) 7.Finding Inverse using Gauss Jordan Elimination (video) 8.Finding Inverse using Gauss Jordan Elimination-Python code Vectors in Machine Learning- Basics 9.Vector spaces and sub spaces 10.Linear Independence 11.Linear Independence, Basis and Dimension (video) 12.Generating set basis and span 13.Rank of a Matrix 14.Linear Mapping...
The Singular Value Decomposition ( SVD) of a matrix is a central matrix decomposition method in linear algebra.It can be applied to all matrices,not only to square matrices and it always exists.It has been referred to as the 'fundamental theorem of linear algebra'( strang 1993). SVD Theorem: Let $A^{m \times n}$ be a rectangular matrix of rank $r \in [0,min(m,n)]$. The SVD of A is a decomposition of the form. $A= U \Sigma V^T $ with an orthogonal matrix $U \in \mathbb{R}^{m \times m}$ with column vectors $u_i, i=1,\ldots,m$ and an orthogonal matrix $V \in \mathbb{R}^{n \times n}$ with column vectors $v_j, j=1,\ldots,n$.Moreover, $\Sigma$ is an $m \times n$ matrix with $\sum_{ii} = \sigma \ge 0$ and $\sigma_{ij}=0, i \ne j$. The diagonal entries $\Sigma_i=1,\ldots,r$ of $\sigma$ are called singular values . $u_i$ are called left singular vectors , and $v_j$ are called right singular vectors .By convention singular values are ordered ie; $\sigma_1 \ge \sigma_2 \ldots \sigma_r \...
Elementary Transformations Key to solving a system of linear equations are elementary transformations that keep the solution set the same, but that transform the equation system into a simpler form: Exchange of two equations (rows in the matrix representing the system of equations) Multiplication of an equation (row) with a constant Addition of two equations (rows) Add a scalar multiple of one row to the other. Row Echelon Form A matrix is in row-echelon form if All rows that contain only zeros are at the bottom of the matrix; correspondingly,all rows that contain at least one nonzero element are on top of rows that contain only zeros. Looking at nonzero rows only, the first nonzero number from the left pivot (also called the pivot or the leading coefficient) is always strictly to the right of the pivot of the row above it. The row-echelon form is where the leading (first non-zero) entry of each row has only zeroes below it. These leading entries are called...
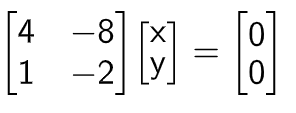
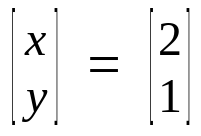

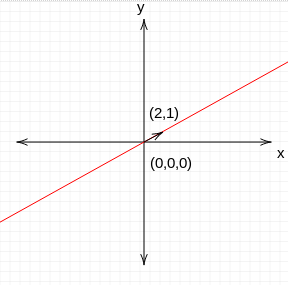 Red line represents the null space of system of linear equations
Red line represents the null space of system of linear equations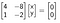
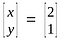
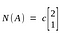
Comments
Post a Comment