A real 

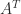
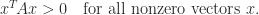
By making particular choices of 

Satisfying these inequalities is not sufficient for positive definiteness. For example, the matrix
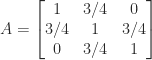
satisfies all the inequalities but 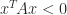
![x = [1,{}-\!\sqrt{2},~1]^T](https://s0.wp.com/latex.php?latex=x+%3D+%5B1%2C%7B%7D-%5C%21%5Csqrt%7B2%7D%2C%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002)
A sufficient condition for a symmetric matrix to be positive definite is that it has positive diagonal elements and is diagonally dominant, that is, 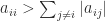

The definition requires the positivity of the quadratic form 
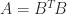


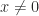
Two equivalent conditions to
- every leading principal minor
, where the submatrix
comprises the intersection of rows and columns
to
, is positive,
- the eigenvalues of
The first condition implies, in particular, that 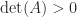
Here are some other important properties of symmetric positive definite matrices.
is positive definite.
, where a square root is a matrix
.
, where
is upper triangular with positive diagonal elements.
Sources of positive definite matrices include statistics, since nonsingular correlation matrices and covariance matrices are symmetric positive definite, and finite element and finite difference discretizations of differential equations.
Examples of symmetric positive definite matrices, of which we display only the 
![H_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} c}@{\mskip 5mu}} 1 & \frac{1}{2} & \frac{1}{3} & \frac{1}{4} \\[6pt] \frac{1}{2} & \frac{1}{3} & \frac{1}{4} & \frac{1}{5}\\[6pt] \frac{1}{3} & \frac{1}{4} & \frac{1}{5} & \frac{1}{6}\\[6pt] \frac{1}{4} & \frac{1}{5} & \frac{1}{6} & \frac{1}{7}\\[6pt] \end{array}\right],](https://s0.wp.com/latex.php?latex=H_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+c%7D%40%7B%5Cmskip+5mu%7D%7D+++++++++++++1+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D++%26+%5Cfrac%7B1%7D%7B4%7D++%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D+++%26+%5Cfrac%7B1%7D%7B4%7D+++%26+%5Cfrac%7B1%7D%7B5%7D%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B4%7D+++%26++++++%5Cfrac%7B1%7D%7B5%7D+++%26+%5Cfrac%7B1%7D%7B6%7D%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B4%7D+%26+%5Cfrac%7B1%7D%7B5%7D+++%26++++++%5Cfrac%7B1%7D%7B6%7D+++%26+%5Cfrac%7B1%7D%7B7%7D%5C%5C%5B6pt%5D++++++++++++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
the Pascal matrix
![P_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} r}@{\mskip 5mu}} 1 & 1 & 1 & 1\\ 1 & 2 & 3 & 4\\ 1 & 3 & 6 & 10\\ 1 & 4 & 10 & 20 \end{array}\right],](https://s0.wp.com/latex.php?latex=P_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+r%7D%40%7B%5Cmskip+5mu%7D%7D++++++1+%26++++1++%26+++1++%26+++1%5C%5C++++++1+%26++++2++%26+++3++%26+++4%5C%5C++++++1+%26++++3++%26+++6++%26++10%5C%5C++++++1+%26++++4++%26++10++%26++20++++++++++++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
and minus the second difference matrix, which is the tridiagonal matrix
![S_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} r}@{\mskip 5mu}} 2 & -1 & & \\ -1 & 2 & -1 & \\ & -1 & 2 & -1 \\ & & -1 & 2 \end{array}\right].](https://s0.wp.com/latex.php?latex=S_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+r%7D%40%7B%5Cmskip+5mu%7D%7D++++++2+%26+++-1++%26++++++%26++++%5C%5C+++++-1+%26++++2++%26++-1++%26++++%5C%5C++++++++%26++++-1+%26+++2++%26++-1+%5C%5C++++++++%26+++++++%26++-1++%26++2++++++++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
All three of these matrices have the property that 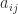
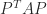

A

What is the best way to test numerically whether a symmetric matrix is positive definite? Computing the eigenvalues and checking their positivity is reliable, but slow. The fastest method is to attempt to compute a Cholesky factorization and declare the matrix positivite definite if the factorization succeeds. This is a reliable test even in floating-point arithmetic. If the matrix is not positive definite the factorization typically breaks down in the early stages so and gives a quick negative answer.
Symmetric block matrices

often appear in applications. If
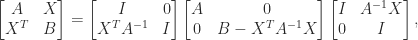
which shows that 
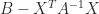
We mention two determinantal inequalities. If the block matrix 
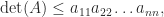
with equality if and only if
Finally, we note that if 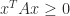
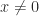



which has leading principal minors 
A complex 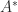
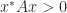
A=np.array([[1,1,2],[2,2,3],[1,3,1]])
B=A.dot(A.T)
print("Symmetric positive definite Matrix B")
print(B)
x=np.array([1,2,3])
print("x.T A x >0")
print(x.T.dot(B.dot(x)))
eigva,eigv=np.linalg.eig(B)
print("eigen values")
print(eigva)
print("eigen vectors")
print(eigv)
Symmetric positive definite Matrix B [[ 6 10 6] [10 17 11] [ 6 11 11]] x.T A x >0 381 eigen values [30.82496889 0.04141054 3.13362056] eigen vectors [[-0.42376703 -0.82534407 -0.37313358] [-0.73151695 0.55478298 -0.39635691] [-0.53413898 -0.10499055 0.83885191]]
Comments
Post a Comment